
Pourquoi des sermons ?
Lors de mes premières recherches sur la langue des protestants, à la suite de ma thèse, je suis tombée un peu par hasard sur des sermons dont un aspect m’a beaucoup touchée : ils « collaient » aux circonstances de l’élocution, on entendait pratiquement « parler » les pasteurs. Pour une historienne de la langue, cette impression d’entendre parler le passé est très rare, puisque l’écrit, en principe, ne laisse guère de place à l’oral. Or, on trouve dans certains sermons des traces émouvantes, comme lorsque Calvin fait référence à l’emploi du temps de la matinée passée, ou Maurice à une collecte effectuée pour soulager les victimes d’un incendie.

Calvin, Jean (1555), Deux Sermons sur ces parolles.

Maurice, Antoine (1722), Sermons sur divers textes de l’Ecriture Sainte.
Il m’a donc semblé que nous avions là un gisement de textes très proches des circonstances de l’élocution, parfois même de l’oral, qui n’avaient jamais été exploités systématiquement en histoire de la langue. Bien entendu, le passage à l’écrit, et plus encore à l’imprimé va induire de nombreux changements, en tout cas dans certains textes.
Ainsi, les marques de l’oral, normalement présentes lors de la performance elle-même, subiront-elles parfois des remaniements, seront-elles filtrées, voire expurgées, lors du passage progressif vers un texte écrit élaboré, digne d’être publié, un «oral scripturalisé» (Adam 2005:140), mais certaines marques de l’énonciation (adresses à l’auditoire, « Mes frères ») resteront très présentes, ce qui est très intéressant du point de vue de la pragmatique.
Pourquoi cette époque et ce lieu de publication ?
Le corpus SERMO est à la fois large du point de vue diachronique, et restreint du point de vue diatopique. Il permet ainsi de mettre à jour et de décrire les caractéristiques linguistiques et discursives du genre des sermons et leur évolution sur deux siècles (1550-1750). Le lieu d’édition choisi pour ce corpus, Genève, permet l’accès à un grand nombre de textes (62 sermons représentant 600’550 tokens) sur toute la période envisagée. En effet, c’est le seul lieu où les textes protestants ont pu être édités sans entrave, dès la Réforme et jusqu’au milieu du XVIIIe siècle, période choisie pour notre étude. Le fait que le lieu soit unique permet d’observer l’évolution diachronique sans trop d’interférence d’autres phénomènes dus à la variation géographique. Comme nous le voyons, l’empan diachronique nous amène vers le français pré-classique et classique, avec toutes les évolutions que ces états de langue ont connues.
Présentation du travail et de la chaîne de traitement
Pour toutes les étapes techniques du traitement du corpus, les outils existants ont dû être adaptés à l’état de langue du français des XVIe, XVIIe et XVIIIe siècles, ce qui a permis d’améliorer grandement leur performance. Par exemple, l’outil utilisé pour définir la catégorie grammaticale de chaque mot (POS-Tagging), TreeTagger, a vu son pourcentage de réussite croître significativement avec l’ajout d’un dictionnaire de longueur limitée, alors que sa réussite chutait, avec l’ajout de trop d’informations.
Une partie de la chaîne de traitement a été faite automatiquement ou semi-automatiquement : Tokenisation (automatique) : utilisation du lexique basé sur le corpus du moyen français (projet PRESTO) enrichi avec les formes spécifiques au corpus SERMO ; Lemmatisation (automatique) avec la prise en compte de la variation graphique, sur la base de l’outil LGeRM ; Étiquetage morpho-syntaxique (POS-tagging) (automatique) : TreeTagger (outil de segmentation et le modèle de langue pour le balisage des catégories grammaticales) avec le modèle de langue développé d’abord par le projet PRESTO, et ensuite adapté à l’état de langue du corpus SERMO ; Contrôle et correction de POS (Part of speech) (semi-automatique).
La véritable plus-value du corpus SERMO pour la recherche est constituée par la partie manuelle de la chaîne de traitement, à savoir les annotations formelles (saut de page ; saut de colonne ; réclame ; image ; titre ; sous-titre ; manchette ; lettrine ; gras ; italique ; souligné) ou autres (source ; commentaire métadiscursif ; citation biblique ; date du sermon ; note de l’auteur ; référence biblique ; autre référence ; discours direct).
Qui peut travailler avec ce corpus ?
Une des ambitions du projet SERMO était de ne pas faire de choix qui restreindraient le public cible. Le corpus doit être préservé de toute intervention qui en fausserait l’interprétation. Choisir, c’est déjà interpréter. C’est pourquoi, tous les balisages et tous les traitements que nous avons faits avaient pour but de permettre aux chercheurs de différentes disciplines de faire leurs propres choix. Voici quelques illustrations de recherches en fonction de différents publics.
1.Historiens du livre
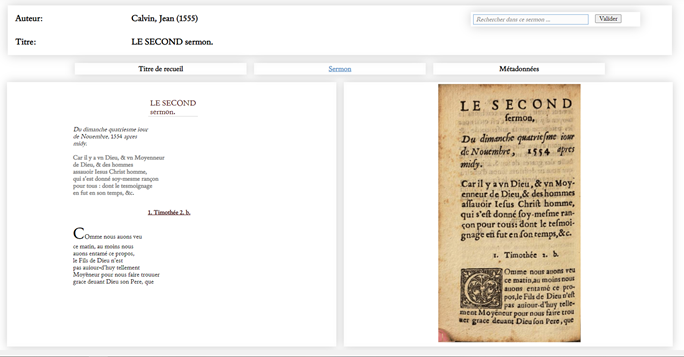
L’ensemble de la collection est visible par des photos des textes qui permettent d’observer la mise en page, les caractéristiques de l’impression, etc., en miroir de leur transcription, et les métadonnées.
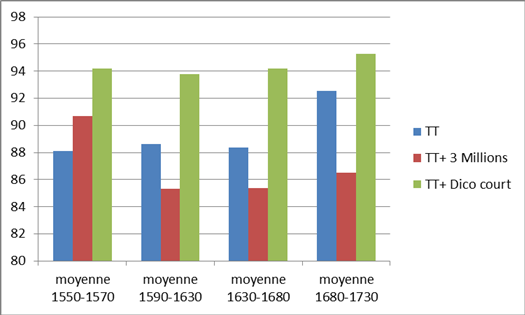
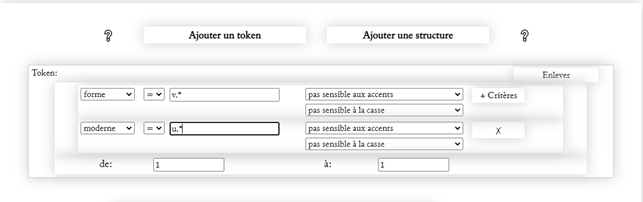
Le respect de la graphie permet d’analyser l’histoire de l’imprimerie. Par exemple, on peut chercher tous les mots qui commencent par un « u » dans la graphie moderne mais qui sont graphiés « v » dans la forme ancienne, et observer leur graphie et son évolution avec le temps, grâce à l’outil « Distribution ».
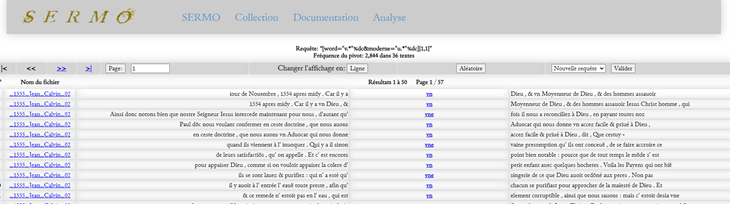
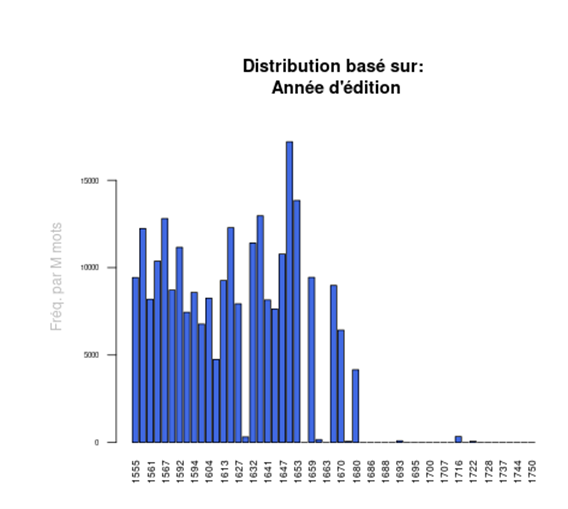
La fonction « Distribution » montre clairement que l’utilisation de la lettre « v » pour notre « u » moderne a disparu à la fin du XVIIe siècle.
2.Théologiens / historiens des idées
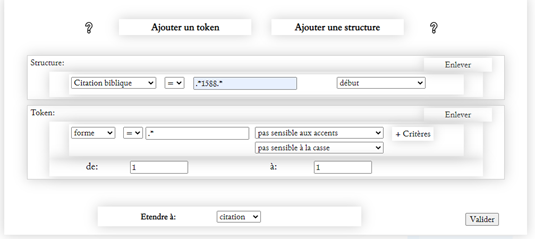
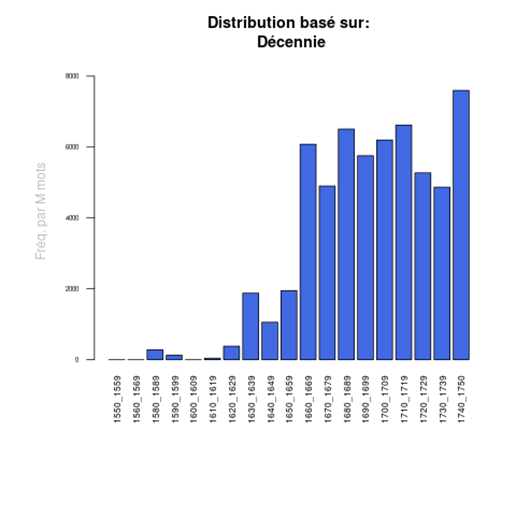
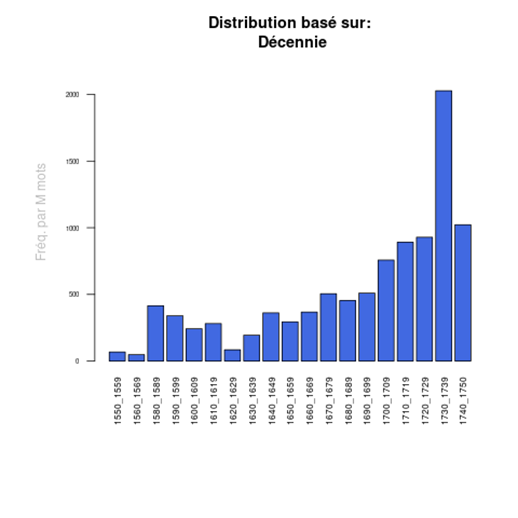
Les historiens des idées peuvent par exemple vouloir étudier l’influence de tel ou tel théologien, réformateur ou traducteur, en observant, par exemple, de quelle Bible les pasteurs et auteurs des sermons tiraient leurs citations. On sait, par exemple, que la Bible de 1588, dite Bible de Genève, qui doit beaucoup à Calvin, est devenue assez rapidement une référence, au point qu’on l’a qualifiée de « Vulgate protestante ». On peut facilement en voir l’impact en recherchant dans le corpus les sources des citations bibliques par la recherche suivante :
Puis, après avoir ouvert le concordancier qui affiche toutes les citations, on peut en demander la distribution dans le temps, par décennie par exemple :
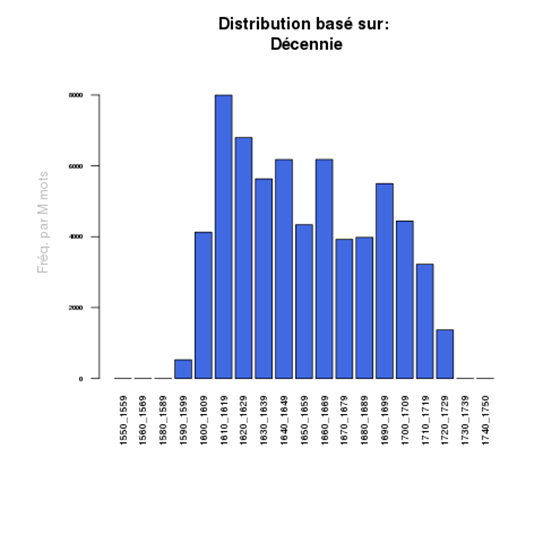
Ce qui nous montre clairement la rapidité et l’importance de l’impact de cette traduction particulière.
3.Historiens de la langue
Il s’agit du véritable public cible de ce projet. En effet, rares sont les corpus suffisamment cohérents et outillés pour pouvoir observer de manière à la fois quantitative et qualitative l’évolution de la langue dans la période préclassique. Voici deux exemples de recherches, parmi de très nombreuses autres possibilités.
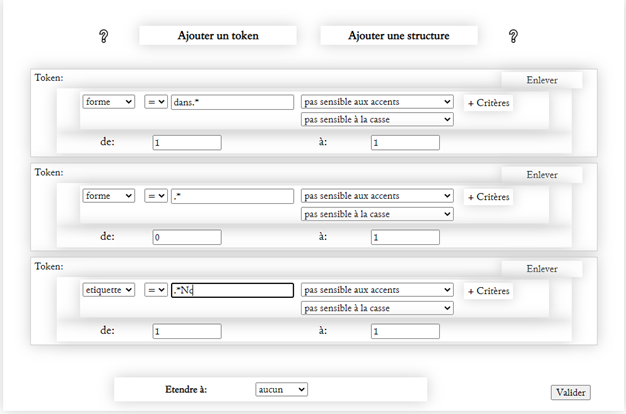
Au niveau de la microsyntaxe, on peut observer sur deux siècles des changements difficilement repérables par l’analyse « manuelle ». Par exemple, on sait que pendant notre période (1550-1750) a lieu un changement dans l’utilisation des prépositions : Alors qu’on avait p.ex. dedans + Syntagme nominal, comme chez Théodore de Bèze (1586) « Dieu le Createur s’insinuoit dedans ses creatures », on trouvera de plus en plus souvent les formes moderne dans + Syntagme nominal, comme chez Jacquelot (1750). « Alors la gloire & la prospérité , qui vous environne , ne pourra alterer ni corrompre dans votre Ame le doux sentiment de la paix de Dieu ». Pour pouvoir observer précisément l’évolution de ces formes, on ne peut pas se contenter de les chercher en tant que telles, mais il faut sélectionner uniquement les cas où ces prépositions sont suivies de syntagmes nominaux. Cette dernière requête est possible grâce à l’étiquetage morphosyntaxique réalisé et contrôlé sur tout le corpus. La recherche ne doit par ailleurs être exécutée que dans le texte des sermons, à l’exclusion des titres, sous-titres et citations qui sont souvent archaïsantes, notamment par la référence majoritaire à la Bible de 1588 évoquée ci-dessous. Ces critères amènent donc à la recherche suivante :
Dedans + SN
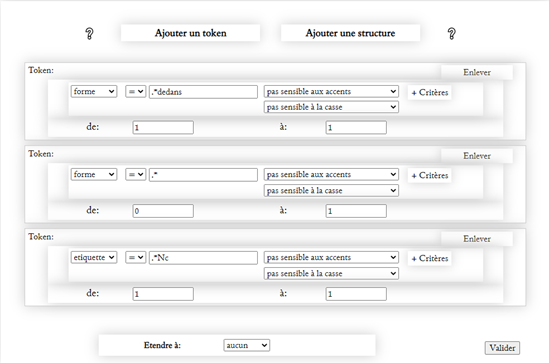
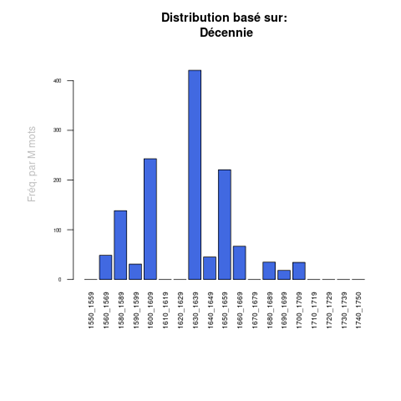
Dans+ SN

Autre exemple en microsyntaxe, la place du pronom clitique avec un semi-auxiliaire (vouloir, devoir, pouvoir), qui a changé sur la période, passant de « je le veux voir » à « je veux le voir ». Une recherche sur la construction émergente, en prenant soin d’exclure les citations archaïsantes nous montre ceci :
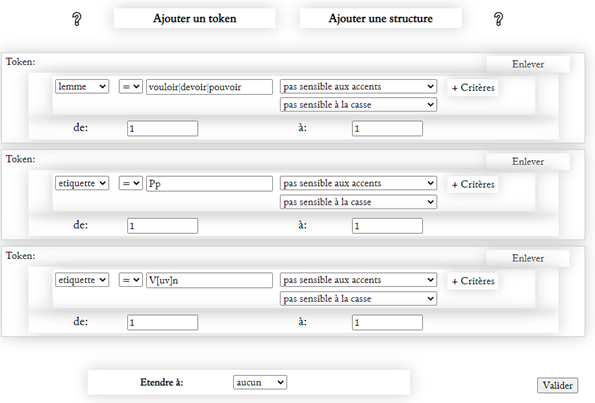

D’autres requêtes au niveau macrotextuel peuvent être réalisées, comme la recherche de toutes les conjonctions de coordination en tête de phrase, qui nous indiquent la manière dont la cohérence textuelle est assurée. Pour faire bref, on observe à ce sujet un changement spectaculaire, les conjonctions dans cette position étant toujours moins nombreuses, alors que ce sont les pronoms personnels en tête de phrase qui reprennent cette fonction.
Bref, les quelques requêtes présentées ici nous montrent que les corpus de textes historiques outillés comme SERMO permettent à de nombreuses personnes, quelle que soit l’objet de leurs recherches, de trouver en quelques clics réponses à leurs questions.
Suggested citation: Skupien Carine, Présentation du corpus SERMO : Qu’est-ce qu’un corpus de sermons protestants du XVI-XVIIIe siècle peut nous apprendre sur la langue ?, Blog of the LexTech Institute, 9 November 2021
